

HOSPITAL ACQUIRED INFECTIONS PROJECT
- okanhasturkk
- May 11
- 4 min read
Updated: Jun 24
This is my Excel Project using real data obtained from State of New York. I analyzed this dataset without having any healthcare background. My motivation within this project was to be able to clean, standardize and visualize data without having any knowledge and have a sufficient exploratory data analysis.
Dataset Source: https://health.data.ny.gov/Health/Hospital-Acquired-Infections-Beginning-2008/utrt-zdsi/about_data
File:


Upon cleaning the data, I came across some bad spelling, which mostly consisted of punctuation mistakes, and some spacing issues. I corrected some of these issues with formulas and some with formulas.

Here are some formulas that I have applied.





This was the the data cleaning - standardization part. Afterwards, comes the EDA (exploratory data analysis) part of my analyze. I must stress here that the EDA part consists only of the SIR (Standardized Infection Rate) calculation which is obtained by the proportion of observed infections to the predicted infections, which I learned by reading the Information file found at the dataset source additionally. I am aware that there are other conditions that apply to this. Because this dataset includes time and calculation, I opted for these 3 dimensions. Time, Infections observed, Infections Predicted and the SIR. The EDA phase of the project consists of these 4 elements only. In these comparisons, hospitals that include ALL in their name, were excluded to concentrate on individual hospitals.



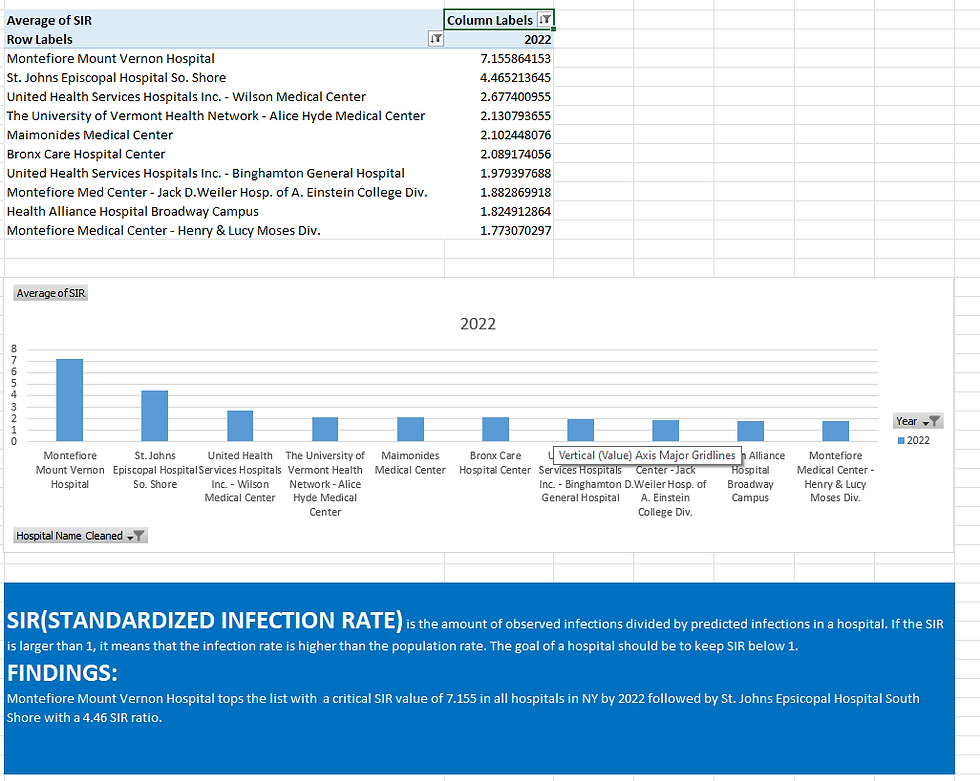
Here are examples of how I filtered and sorted the pivot table.


In my last Tab, I analyzed some of SIR values by conditional formatting and entered a XLOOKUP formula for a specific value. Here is how it looks.



And my final calculation is to determine the SIR value of a random hospital, which I have done with the help of XLOOKUP function because it requires searching through large arrays.




Comments