

NY STATE CENSUS POPULATION 2010-2020
- okanhasturkk
- May 11
- 8 min read
Updated: Jun 25
My SQL project, in which I cleaned, standardized, analyzed and transformed raw real population census data of NY from years 2010 and 2020 using MySQL. All of the steps and processes are described below.
Dataset Source: https://data.ny.gov/Economic-Development/Census-2010-and-2020-Population-Region-Counties-Ci/sxhg-qquj/about_data
Link to code: https://github.com/Hawog86/Okan_Hasturk_Portfolio/blob/main/Census%202010%20and%202020%20population.sql
First, let's have a look at the data.

Then, let's check for NULL values.
SELECT *
FROM census
WHERE `Area Type` IS NULL OR `Area Name` IS NULL OR `Population Percent Change` IS NULL OR `2010 Census Population` IS NULL OR `2020 Census Population` IS NULL OR `Population Change` IS NULL OR `Population Percent Change` IS NULL
;Upon executing the code on all of columns, the result is as it follows.

Now, let's do the same for 0 values for integer and BLANK values for string datatypes.
SELECT *
FROM census
WHERE `Area Type` = '' OR `Area Name` = '' OR `Population Percent Change` = 0 OR `2010 Census Population` = 0 OR `2020 Census Population` = 0 OR `Population Change` = 0 OR `Population Percent Change` = 0
;Upon executing the code on all of columns, the result is as it follows.

Now, it is time to check for duplicate values with the help of COUNT function.
SELECT `Area Type`, COUNT(`Area Type`)
FROM census
GROUP BY `Area Type`
;It must be stated here the use of "`" are to choose from the column name because it consists of two names that are not joined with the"_". Instead, the use of "`" are preferred throughout the whole code. In addition, because COUNT is an aggregate function, the use of GROUP BY statement is imperative.

SELECT `Area Name`, COUNT(`Area Name`)
FROM census
GROUP BY `Area Name`
HAVING COUNT(`Area Name`) > 1
;
The reason for using HAVING statement is that, because COUNT is an aggregate function, which can be queried through the GROUP BY statement, any querying within GROUP BY can only be done with HAVING because it applies to an aggregate function.
Now, let's check these potential duplicates if they are indeed duplicates. If they return, the same numeric values, they are duplicates.
SELECT *
FROM census
WHERE `Area Name` LIKE '%New York City%' OR `Area Name` LIKE '%Dickinson Town%' OR `Area Name` LIKE '%Chester Town%' OR `Area Name` LIKE '%Greenville Town%' OR `Area Name` LIKE '%Brighton Town%' OR `Area Name` LIKE '%Franklin Town%' OR `Area Name` LIKE '%Lewis Town%' OR `Area Name` LIKE '%Albion Town%' OR `Area Name` LIKE '%Clinton Town%' OR `Area Name` LIKE '%Ashland Town%' OR `Area Name` LIKE '%Fremont Town%' OR `Area Name` LIKE '%Morris Town%' OR `Area Name` LIKE '%York Town%' OR `Area Name` LIKE '%Beekman Town%' OR `Area Name` LIKE '%German Town%' OR `Area Name` LIKE '%Orange Town%'
;
In order to query the same town names, LIKE operator has been selected here and the query has been made by searching the whole town name which was enabled by the "%" which means including multiple characters.
Though so far the data set looked clean, there were some area names which included 'town' multiple times. First, these area names have to be determined with the help of this query. REGULAR EXPRESSIONS and METACHARACTERS are going to be used for this query for identifying.
SELECT `Area Name`, REGEXP_LIKE (`Area Name`,'town') AS names_including_town
FROM census
GROUP BY `Area Name`
HAVING names_including_town > 0;The selection of REGEXP_LIKE as a regular expression method is to determine the pattern which is including the word 'town' here. If the query has town in the Area Name column, it is going to return 1. And there is an aliasing here as well to describe the new column through AS operator.

In order to identify this pattern of names, this names of the Area names that ends with 'town' has to be identified first.
SELECT `Area Name`
FROM census_raw
WHERE `Area Name` REGEXP 'town$'
;"$" metacharacter is chosen for the ends with condition in the WHERE statement to generate this condition.
After the identification of those area names, the spaces between the towns will be removed to make the Area name whole as "Watertowntown". For that, subquery will be needed.
SELECT `Area Name`, REGEXP_REPLACE(`Area Name`, '[ ]', '')
FROM census
WHERE `Area Name` IN
(SELECT `Area Name`
FROM census
WHERE `Area Name` REGEXP 'town$'
)
;In the subquery, the area names that end with town, which is shown above this query has been executed. And only after, identifying those names the space removal between multiple 'town's can be realized. The space removal has been done with REGEXP_REPLACE command defining space as '[ ]' and replacing it with '' thus obtaining the following result.

In order to apply this update to the dataset, the whole dataset has to be updated. This will be realized by UPDATE statement.
UPDATE census
SET `Area Name` = REGEXP_REPLACE(`Area Name`, '[ ]', '')
WHERE `Area Name` REGEXP 'town$'
;After the update, the Area names that end with 'towntown' has to be identified.
SELECT `Area Name`
FROM census
WHERE `Area Name` REGEXP 'towntown$'
;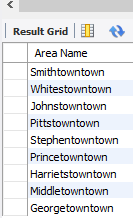
As done previous with the space removal between town, the same exact method will be applied to those 21 rows.
SELECT `Area Name`, REGEXP_REPLACE(`Area Name`,'towntown', 'town')
FROM census
WHERE `Area Name` REGEXP 'towntown$'
;
After changes, updating is required.
UPDATE census
SET `Area Name` = REGEXP_REPLACE(`Area Name`,'towntown', 'town')
WHERE `Area Name` REGEXP 'town$'
;SELECT *
FROM census
WHERE `Area Name` REGEXP 'towntown$'
;After updating the dataset, checking if all updates have been applied correctly, and the result is:

Another issue that has been detected was the Area names that end with 'town' has no space before it, so now this issue is going to be addressed with the help of CONCATENATE, SUBSTRING_INDEX and RIGHT commands. SUBSTRING_INDEX will be used to defragment the 'town' from the Area Names, that ends with 'town'; RIGHT will be used to determine the position to add the space before 'town', which is 4 from the end and CONCATENATE will be used to add the space between those 2 and generate the proper Area Name.
SELECT `Area Name`, CONCAT(SUBSTRING_INDEX(`Area Name`,'town',1),
' ',RIGHT(`Area Name`,4))
FROM census
WHERE `Area Name` REGEXP 'town$'
;
As always, update after modification.
UPDATE census
SET `Area Name` = CONCAT(SUBSTRING_INDEX(`Area Name`,'town',1),
' ',RIGHT(`Area Name`,4))
WHERE `Area Name` REGEXP 'town$'
;Another detected issue was the presence of unnecessary dash within Area Names. They will be removed with the exact same method before.
SELECT `Area Name`, REGEXP_REPLACE(`Area Name`,'-',' ')
FROM census
WHERE `Area Name` REGEXP '-'
;
Updating the database after modification.
UPDATE census
SET `Area Name` = REGEXP_REPLACE(`Area Name`,'-',' ')
WHERE `Area Name` REGEXP '-'
;Till this point, it was data cleaning and standardization. From this point on, Exploratory Data Analysis Phase. Before this phase, all data will be checked one more time.
At First, in our database there is a calculation already which is the population difference between 2020 and 2010. Let's be sure if this calculation is done right with the help of a CASE statement in a SUBQUERY.
SELECT *
FROM
(
SELECT `Population Change`,
CASE
WHEN `2020 Census Population` - `2010 Census Population` = `Population Change` THEN TRUE
ELSE FALSE
END AS Population_Difference_Comparison
FROM census) AS Check_Table
WHERE Population_Difference_Comparison = 0
;Within the SUBQUERY, including the CASE statement and ALIASING, a simple operation is performed; if the difference of population of 2020 to 2010 has been calculated correctly, the end result should be 1, otherwise 0. In the main query, the search has been applied to find a 0 which represents a miscalculation or mistake.

Time to do the same for the Population Percent Change Column:
SELECT `Population Percent Change`,
CASE
WHEN (`2020 Census Population` - `2010 Census Population`) / `2010 Census Population` = `Population Percent Change` THEN TRUE
ELSE FALSE
END AS Population_Percent_Change_Comparison
FROM census
;
Because there are 4 decimal digits visible, I will try to ROUND the calculation to 4 digits to check if this might be the issue and applying the previous SUBQUERY.
SELECT *
FROM
(
SELECT `Population Percent Change`,
CASE
WHEN ROUND((`2020 Census Population` - `2010 Census Population`) / `2010 Census Population`,4) = `Population Percent Change` THEN TRUE
ELSE FALSE
END AS Population_Percent_Change_Comparison
FROM census
) AS ppcr_Table
WHERE Population_Percent_Change_Comparison = 0
;
Now, I am going to dive into some trends and comparisons. Let's check the ranking of the cities whose population have increased and let's sort them by Population Change. For this, WINDOW FUNCTION is required and I will be using RANK and PARTITION BY.
SELECT *,
RANK() OVER(PARTITION BY `Area Type` ORDER BY `Population Change` DESC) AS Population_Increase_Ranking
FROM census
WHERE `Area Type` = 'City' AND `Population Change` >= 0
;For conditions WHERE statement is used to filter city and positive population change. Ranking has been filtered for Area Type and Population Change in descending order.

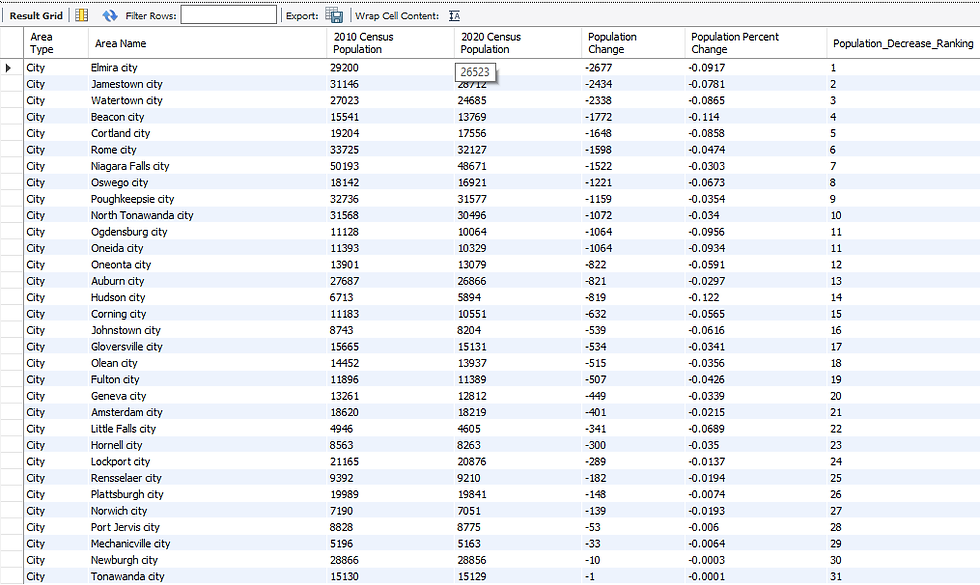
Let's do the same ranking for the Population Decrease Amount by cities this time.
SELECT *,
DENSE_RANK() OVER(PARTITION BY `Area Type` ORDER BY `Population Change` ASC) AS Population_Decrease_Ranking
FROM census
WHERE `Area Type` = 'City' AND `Population Change` <= 0
;Dense Rank has been chosen this time in case the same ranking might occur and because the ranking has been applied to a negative value, ascending order has been chosen.
SELECT *,
DENSE_RANK() OVER(PARTITION BY `Area Type` ORDER BY `Population Change` ASC) AS Population_Decrease_Ranking
FROM census
WHERE `Area Type` = 'City' AND `Population Change` <= 0
;
In the upcoming 6 queries, the exact rankings has been applied to town, county and village of Area Name column.
Now, I am gonna look into top 5 villages whose population have increased. I will use ROW_NUMBER and SUBQUERY.
SELECT *
FROM
(
SELECT *,
ROW_NUMBER() OVER(PARTITION BY `Area Type` ORDER BY `Population Change` DESC
) AS Row_Num
FROM census
WHERE `Area Type` = 'Village' AND `Population Change` >= 0) AS Row_Table
WHERE Row_Num <= 5
;SUBQUERY has been applied to determine and choose from the top 5 villages according to their ROW NUMBER, because where can not be applied to the WINDOW FUNCTION directly.

And the final comparison is made for the top 7 towns with highest population decrease. LIMIT has been preferred this time.
SELECT *,
ROW_NUMBER() OVER(PARTITION BY `Area Type` ORDER BY `Population Change` ASC) AS Row_Num
FROM census
WHERE `Area Type` = 'Town' AND `Population Change` <= 0
LIMIT 7
;



Comments